최근 인공지능 기술이 급수적으로 발전하면서, 수많은 AI 연구소와 기업들이 앞다투어 자사 대형 언어 모델(LLM)의 무료 API 티어를 제공하고 있습니다. 덕분에 개인 개발자나 연구자들은 큰 비용을 들이지 않고도 최신 모델들을 테스트해 볼 수 있는 좋은 환경이 마련되었죠.
하지만 막상 이것들을 실제 프로젝트나 장기적인 테스트에 적용하려고 하면 예상치 못한 문제에 직면하게 됩니다. 각 서비스마다 API 규격이 다르고, 무엇보다 무료 티어 특성상 빈번하게 발생하는 ‘요청 한도 초과(Rate Limit)’ 때문에 시스템이 중간에 멈춰버리기 일쑤이기 때문입니다. 이러한 불편함을 단번에 해결하고 여러 무료 API를 하나의 거대한 자원으로 묶어주는 흥미로운 오픈소스 프로젝트가 있습니다. 바로 FreeLLMAPI입니다.
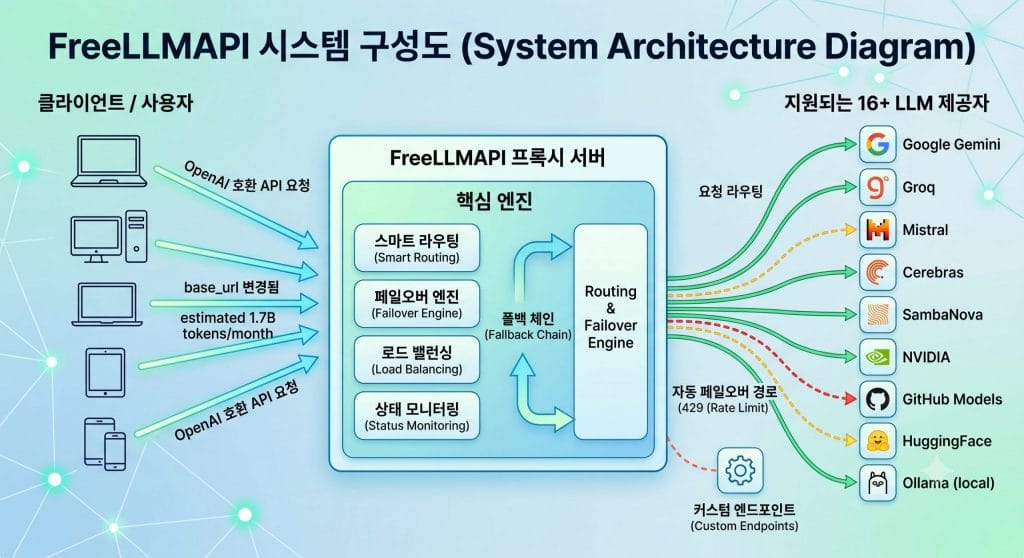
1. 매달 17억 토큰의 자유, FreeLLMAPI 개요
FreeLLMAPI는 무려 16개 이상의 다양한 LLM 제공자(Google Gemini, Groq, Mistral, GitHub Models 등)의 무료 티어를 한데 모아, 단 하나의 OpenAI 호환 엔드포인트 뒤로 묶어주는 강력한 프록시(Proxy) 서버 역할을 합니다.
원작자의 설명에 따르면, 이 도구를 통해 하나로 합칠 수 있는 추론 용량이 매달 약 17억(1.7B) 토큰에 달한다고 한다. 100개가 넘는 다양한 모델들을 단일 인터페이스 안에서 손쉽게 호출할 수 있다는 점은 가벼운 토이 프로젝트나 아이디어 검증을 진행할 때 엄청난 메리트로 다가온다. 복잡하게 흩어진 자원들을 영혼까지 끌어모아 나만의 든든한 백엔드를 구축하는 셈입니다.
2. 끊김 없는 운영의 비밀, 스마트 라우팅과 페일오버(Failover)
여러 무료 API를 섞어 쓸 때 가장 큰 골칫거리는 툭하면 튀어나오는 ‘429 Too Many Requests’ 에러입니다. FreeLLMAPI는 이 문제를 영리하게 해결했습니다.
핵심 원리는 바로 지능형 라우팅과 자동 우회(Failover) 시스템에 있습니다. 사용자의 요청이 프록시 서버로 들어오면, 엔진은 1순위로 지정된 제공자에게 요청을 보낸다. 만약 여기서 한도 초과나 연결 오류가 발생하더라도 사용자에게 곧바로 에러를 뱉어내지 않습니다. 그 즉시 2순위, 3순위의 다른 제공자로 트래픽을 넘겨(Fallback) 매끄럽게 응답을 받아오죠. 사용자는 뒤에서 어떤 API가 죽었고 다른 경로로 우회되었는지 전혀 신경 쓸 필요 없이 그저 안정적으로 결과물만 받아보면 됩니다.
– 작동원리
FreeLLMAPI는 일종의 ‘중개자(Wrapper)’ 역할을 수행합니다.
- 요청 수신: OpenAI API 규격(
v1/chat/completions)으로 들어오는 데이터를 가로챕니다. - 변환 및 전달: 요청 내용을 로컬 환경에 설치된 LLM이 이해할 수 있는 형식으로 변환하여 전달합니다.
- 응답 반환: 로컬 모델의 결과값을 다시 OpenAI API 응답 규격(JSON 형태)으로 포맷팅하여 클라이언트에게 전송합니다. 이 과정 덕분에 개발자는 내부 로직을 수정하지 않고도 백엔드 모델만 쉽게 교체할 수 있습니다.
3. 직관적인 설치와 세팅 방법
강력한 기능에 비해 설치 방법은 매우 간결합니다. Node.js 20 이상 환경이 구축되어 있다면 소스코드를 직접 클론하여 의존성을 설치하고 바로 실행할 수 있다.
하지만 운영의 편의성을 고려한다면 도커(Docker) 기반의 배포를 적극 권장합니다. 라즈베리 파이 같은 ARM 아키텍처까지 지원하는 공식 멀티 아키텍처 이미지(ghcr.io/tashfeenahmed/freellmapi)를 제공하기 때문입니다. NAS나 개인용 홈 서버의 터미널에 아래와 같은 명령어 한 줄만 입력하면 그 즉시 서버가 구동된다.
서버가 띄워지면, 각 LLM 제공자에서 발급받은 무료 API 키들을 환경 설정이나 대시보드(혹은 설정 파일)에 입력해 두기만 하면 준비는 끝납니다.
– 설치법
파이썬 환경이 구축되어 있어야 합니다.
- 리포지토리 복제
git clone https://github.com/tashfeenahmed/freellmapi.git
cd freellmapi- 종속성 설치
pip install -r requirements.txt4. 손쉬운 사용법과 AI 에이전트(Agent) 운영의 시너지
기존에 OpenAI SDK나 LangChain 기반으로 코딩을 해두었다면, 코드를 통째로 갈아엎을 필요가 전혀 없습니다. 클라이언트 초기화 코드에서 base_url을 로컬에 띄운 FreeLLMAPI 서버 주소(예: http://localhost:8000/v1)로 살짝 바꿔주기만 하면 기존 로직이 그대로 동작합니다.
특히 이 시스템은 AI 에이전트를 운영할 때 완벽한 시너지를 발휘합니다. 자율형 에이전트(AutoGPT 등)는 스스로 계획을 세우고, 검색하고, 코드를 짜느라 짧은 시간 안에 API를 무자비하게 호출합니다. 단일 무료 API로는 몇 분도 안 되어 Rate Limit에 걸려 에이전트가 멈춰버리지만, FreeLLMAPI의 페일오버 체인을 걸어두면 한 제공자의 한도를 다 쓰더라도 다음 제공자로 자연스럽게 넘어가며 24시간 내내 에이전트를 끊김 없이 굴릴 수 있죠.
서버를 실행하고 클라이언트 코드에서 접속 경로(base_url)를 변경합니다.
- 서버 실행
python app.py --model [모델명/경로] --port 8000- 연결 코드 예시
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="local" # 로컬이므로 보안 키는 불필요
)
# 이후 표준 OpenAI 라이브러리 사용법과 동일- 기존 코드 연결하기
from openai import OpenAI
# 로컬 서버 주소로 변경하여 연결
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="not-needed" # 로컬이므로 별도의 키는 필요하지 않습니다.
)
response = client.chat.completions.create(
model="your-local-model",
messages=[{"role": "user", "content": "로컬 LLM 서버 구축 성공!"}]
)
print(response.choices[0].message.content)5. API 끌어오기 vs 로컬 LLM 직접 구동, 승자는?
그렇다면 외부 API를 프록시로 끌어오는 방식과 내 PC에서 Ollama나 llama.cpp를 이용해 로컬 LLM을 직접 구동하는 것은 어떤 차이가 있을까요? 각자의 목적에 따라 뚜렷한 장단점이 존재한다.
1. 하드웨어 사양의 제약 극복 가장 큰 차이는 하드웨어 의존성입니다. 로컬 LLM은 수십~수백억 개의 매개변수를 직접 연산해야 하므로 막대한 VRAM을 갖춘 고성능 GPU가 필수적입니다. 반면 API 연동 방식은 텍스트를 던지고 결과만 받아오는 ‘통신’만 수행하면 됩니다. VRAM이 1MB도 없는 구형 사무용 랩톱이나 라즈베리 파이에서도 수천억 파라미터급의 최고급 모델을 순식간에 구동할 수 있다는 것이 API 프록시의 압도적 장점입니다.
2. 오프라인 환경과 안정성 로컬 구동은 초기 하드웨어 투자 비용만 극복하면 인터넷이 완전히 끊긴 산속에서도 완벽하게 동작합니다. 반면 API 기반은 인터넷 연결 속도에 응답 속도가 좌우되며, 외부 서버 장애나 해당 기업의 무료 티어 정책이 변경되면 하루아침에 시스템이 먹통이 될 수 있는 불안정성을 내포하고 있죠.
3. 프라이버시 및 데이터 보안 보안 측면에서는 로컬 LLM의 완승입니다. 사내의 민감한 기밀문서나 개인의 소스코드를 분석할 때, 데이터가 물리적인 내 PC 밖을 한 발짝도 나가지 않습니다. 하지만 FreeLLMAPI를 통해 외부 제공자에게 데이터를 보낼 경우, 16개 기업 각각의 이용 약관(TOS)에 따라 내 질문 데이터가 수집되거나 학습에 쓰일 위험이 존재합니다. 따라서 보안이 중요한 작업에는 로컬 LLM을, 방대한 일반 데이터 처리나 실험적 에이전트 운영에는 API 프록시를 사용하는 식의 하이브리드 전략이 필요합니다.
| 구 분 | 내 용 |
| 장 점 | 비용 절감: API 호출 비용이 발생하지 않음. 데이터 프라이버시: 데이터가 외부 서버로 나가지 않아 보안 우수. 범용성: 기존 OpenAI 생태계(라이브러리/툴)와 완벽 호환. |
| 단 점 | 하드웨어 의존성: 고성능 GPU/RAM 등 로컬 자원을 많이 소모함. 관리 부담: 모델 업데이트 및 서버 최적화를 사용자가 직접 수행해야 함. 성능 제한: 최신 클라우드 기반 초거대 모델에 비해 모델 규모가 작을 수 있음. |
결론적으로 FreeLLMAPI는 하드웨어의 한계에 부딪힌 수많은 1인 개발자와 연구자들에게 거대한 클라우드 인프라를 무료로 빌려 쓰는 듯한 경험을 선사하는 훌륭한 프로젝트입니다. 주말을 활용해 내 PC 한구석에 17억 토큰의 잠재력을 품은 AI 허브를 직접 세팅해 보는 것은 어떨까요?